How would you go about convincing a free market skeptic of the benefits of economic freedom, as opposed to a tightly regulated or even a command economy? A common approach is to discuss productivity gains from free market systems, which reward higher efficiency production as consumers purchase the best and least expensive products. Competition between firms pushes companies to find efficiencies and new production methods.
One might also point out that it’s possible to divide the question of taxation and distribution from that of free market pricing and competition; in other words, if the market skeptic is concerned about the effects of a free market on the unskilled or the handicapped, it’s possible to have a robust safety net and tax system that is built on the most efficient taxes and welfare payments (land value tax, consumption tax, and direct cash grants).
However, today I want to focus on a more amorphous part of the free market, entrepreneurship. The Library of Economics and Liberty has an excellent encyclopedia style article on entrepreneurship written by Russel S. Sobel. He defines an entrepreneur as
…someone who organizes, manages, and assumes the risks of a business or enterprise. An entrepreneur is an agent of change. Entrepreneurship is the process of discovering new ways of combining resources. When the market value generated by this new combination of resources is greater than the market value these resources can generate elsewhere individually or in some other combination, the entrepreneur makes a profit.
Sobel also discusses the approaches of economists Joseph Schumpeter and Israel Kirzner in describing entrepreneurs. Schumpeter is famous for his theory of “creative destruction”, where entrepreneurs are the primary agents of disruption, upending the status quo and altering the market, leaving competitors behind. Kirzner focuses on the aspects of discovery that entrepreneurs perform, as they seek new markets, new processes, and new business models.
We should note that entrepreneurs don’t assume all risks. If their projects fail and the business operates at a loss, they lose their investments. However, if worker jobs are lost not due to performance but poor management, workers might be laid off, which is a risk workers assume, not the entrepreneur. Nonetheless, entrepreneurs likely take on more cumulatively, risking their job and also capital investment. Entrepreneurs are usually thought of in terms of small business owners or startups, but I’d argue many of the roles of an entrepreneur can be undertaken by larger companies. Maybe a publicly traded company cannot, by definition, have an entrepreneur, but if there are still market discovery and disruption operations that the company undertakes due to the search for untapped profit, that’s good enough for our purposes today.
So far, we’ve discussed that entrepreneurs search for market opportunities, new ways of doing business, and undertake risks, but what does this have to do with economic freedom? The benefits of entrepreneurship can be difficult to notice. Sobel uses the examples of Bill Gates and Microsoft which at the very least took over virtually (ha!) the entire personal computer market, and I’d argue created a large new market that hadn’t existed before. However, we don’t know what tomorrow’s entrepreneurs will come up with, and that’s the most vital point. Someone has to envision the new product or service, develop it into something that can be sold, create an organization capable of producing it, and then execute on those plans before the market reacts. If it was well known what needed to be done, it wouldn’t be innovative, and it would already be happening. Entrepreneurs need the freedom to operate, to create new ventures, and to attempt new processes and approaches.
Contrasting with state-run economies or state-owned enterprises, the benefits entrepreneurs bring to a free market economy are pretty straightforward; government enterprises aren’t going to be as profit focused because they don’t reap the benefits of any increase in efficiency. Command economies or highly regulated industries may have price controls imposed on them, and so innovation does not occur because there is no opportunity to do so. Political incentives might also overrule efficiency improvements, and since the state has a hard time going bankrupt, poor rules can hamstring organizations for years. My local DMV still refuses to accept credit cards.
Other forms of economic freedom are more subtle; regulation is a broad form of curtailing economic behavior, although certainly not always for bad purposes. Nonetheless, many well intentioned rules reduce the benefits of innovation or were in fact written with the help of powerful actors looking to keep out competition. Licensing can be especially destructive to innovation; Uber controversially solved this by ignoring licensing laws in many cities until they were too popular to be outlawed (results pending). Taxi licensing had allowed the taxi industry to remain relatively complacent, with poor service, product quality, and ease of use. Uber saw an opportunity to exploit the market with new technology and transformed the industry.
Finally, it’s worth mentioning that a strong defense of property rights is vital for the entrepreneurial process to occur; people will not take risks on new ventures if their asset can be seized at will by the government, or if the currency that transactions are conducted in could lose it’s value overnight (looking at you cryptocurrencies).
Now I’d like to walk through an example of the benefits of entrepreneurship. Netflix was established in 1997 to take advantage of the brand new DVD format for movies. The DVD format was introduced on March 21, 1997, and Netflix was formed by August. That’s an impressively quick turn around. At the time, the most common ways to see entertainment at home was to watch TV shows as they aired, watch movies that had been cut up for TV with commercials when a cable station played them, rent movies from Blockbuster if they had it in stock, or buy the VHS tape of a film.
DVDs had a lot of benefits over VHS when they came out, such as skipping directly to certain scenes, no rewinding, and often better durability than VHS tapes. But Netflix saw that DVDs offered something else: no prior storage format was small enough to be cheaply mailed and large enough to hold an entire film. They foresaw a new method of home rental, and indeed, once DVD players became cheaper in 2001, Netflix took off. They dominated the mail subscription movie rental space, essentially creating a market where none had existed. Unlike movie rental stores, Netflix had a larger catalog and no late fees. Blockbuster was probably in the best position to take advantage of the new DVD technology; they had a pre-existing distribution network for their stores, and they had a customer base interested in movies. Yet Blockbuster peaked in the mid-2000s and filed for bankruptcy in 2010, a victim of Netflix’ creative destruction.
It’s worth mentioning a couple things about Blockbuster. In 2004, they attempted a hostile takeover of competitor Hollywood Video. They abandoned the deal in 2005 citing the FTC would probably block it. Yet both companies were either gone or bankrupt by 2010! The myopia of seeing a merger of Blockbuster and Hollywood Video as threatening to consumers when both companies would be essentially gone in five years underscores the points made here about the value of innovation and entrepreneurship. The state couldn’t look ahead and see that the industry consolidation they were concerned about would have shorter lifespans than many currently airing TV shows. Blockbuster’s competitors were actually Netflix, Redbox, and streaming video–even YouTube, which was founded in 2005 as well. Blockbuster itself made poor management decisions, opting for short term profitability over long term investment for a new industry. They eventually did create an online DVD rental subscription business similar to Netflix, but it was so poorly run, it either lost money or was too expensive to attract customers.
Yet customers did not suffer from this poor management! The entrepreneurship of Netflix filled the void before it even appeared. Netflix leveraged its online presence to profile its users with data, creating personalized recommendations in the mid-2000s, years before Facebook even started running ads. Netflix also saw that the future was streaming video, and noting the success of YouTube, they began including a streaming service with their DVD subscription in 2007. At the time, virtually no one had the bandwidth to watch movies in high quality on their computers, and essentially no technology existed to stream it to TVs. Yet, by 2011, Ars Technica was reporting that Netflix was responsible for about 30% of all North America peak internet traffic.
Netflix had accumulated many streaming titles, but was aware that as the importance of streaming grew, many publishers would be unwilling to renew their contracts, or raise prices. They might even face new streaming competition from content owners (like Hulu). Consequently, Netflix started to invest in original content in 2011, something essentially unheard of for rental/streaming company, by buying the rights to make House of Cards, a political drama, for $100 million. In 2013, it premiered and went on to obtain 5 Primetime Emmy nominations for Outstanding Drama Series from 2013-2017. Other shows, such as Orange is the New Black, the various MCU Defenders series, Bojack Horseman, and Narcos have all been fairly successful. By this year, Netflix’ original programming pieces are in the hundreds if we count all seasons, original films, documentaries, comedy specials, and more. The Economist reports that Netflix will make more TV content than any television network this year, and release 80 movies, more than any Hollywood studio. Warner Brothers, the largest studio, will release just 26, admittedly most with much larger budgets. The critique that Hollywood doesn’t have original ideas is only true if you forget that Netflix is the largest player in Hollywood.
The foresight here for Netflix to to see and invest in the benefits of DVDs in providing by-mail home entertainment, to see streaming as the next iteration of entertainment consumption, and to see that any streaming service will require original content, when none of those markets had yet existed, is the foundation of entrepreneurial benefits. The ability to see where the market will be and adapt your organization to meet those needs in pursuit of profit is the dynamism of the market economy. Other companies’ failures are immediate market feedback on their inability to adapt. It’s not to say that a free market automatically takes advantage of all opportunities that present themselves; sometimes technology has made a new concept viable but no one is able to take advantage of it for some time because of lack of creativity. I also don’t intend to state that large corporations love competition and innovation; on the contrary, they are often trying to remove any competition through any means necessary. Out-competing another company results in better products for consumers; constructing barriers to entry so that consumers don’t have a choice does not.
Finally, given the benefits of entrepreneurship, we should note that it has been declining in the US. Why? It could be due to better economies of scale due to technology, it could be increased regulation has made it harder to form new businesses, it could be reduced labor force participation, or several other theories. Tyler Cowen has discussed this phenomenon in his 2017 book, The Complacent Class. He views it as a possible response to risk avoidance that accompanies increased wealth. Regardless, the questions of why entrepreneurship is declining, and what tradeoffs are involved in the level of dynamism of the economy are the important questions to ask. Dynamic markets are valuable tools to create ideas and innovation that cannot be predicted. Yet lack of clear future benefits should not be counted against the value of economic freedom.

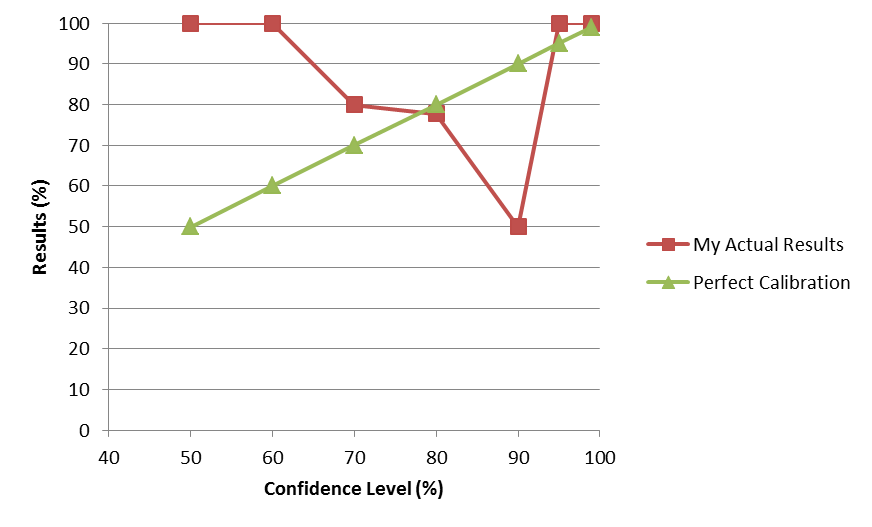 You’re supposed to be as close to the perfect calibration line as possible. The big problems are that I only had 2 or 3 predictions for the 50%, 60%, and 90% confidence intervals. For example, my slip-up on predicting Uber wouldn’t have self-driving cars this year means I was only 1 for 2 on 90% predictions. Clearly I need to find more things to predict, as I had 5 and 9 predictions for the 70% and 80% confidence levels, which were right about on the mark. Luckily for next year, I have almost double the number of predictions:
You’re supposed to be as close to the perfect calibration line as possible. The big problems are that I only had 2 or 3 predictions for the 50%, 60%, and 90% confidence intervals. For example, my slip-up on predicting Uber wouldn’t have self-driving cars this year means I was only 1 for 2 on 90% predictions. Clearly I need to find more things to predict, as I had 5 and 9 predictions for the 70% and 80% confidence levels, which were right about on the mark. Luckily for next year, I have almost double the number of predictions:


{kind=link}
You must be logged in to post a comment.