This is a cross-post from my new substack, Calibrations. Cryptography professor and solid Twitter follow Matthew Green asks why we should really care what prediction markets say:
It would seem the perfect first post for a blog titled Calibrations. So are prediction markets any good at predicting things, and should we care what they say?
Prediction markets allow participants to buy shares of an event occurring or not, analogous to a bet or wager. For example, the website Polymarket has political event markets. A “share” pays out if the election occurs as you predict and pays nothing if you predict incorrectly. A market is created by people buying and selling shares on the outcomes of the events, and the price of the share represents the market’s current probability estimate for the outcome. For example, you can buy a share of Kamala Harris winning the presidential election which will pay out if she wins, but will be worth nothing if she loses. A price of 60 cents would indicate a 60% chance of her winning.
Data on Accuracy
So are prediction markets any good? Well, we can actually look at the history of prediction markets and see how often a market that predicts any given outcome actually ends up resolving in that way. Maxim Lott at electionbettingodds.com has a track record page for the prediction markets he tracks.
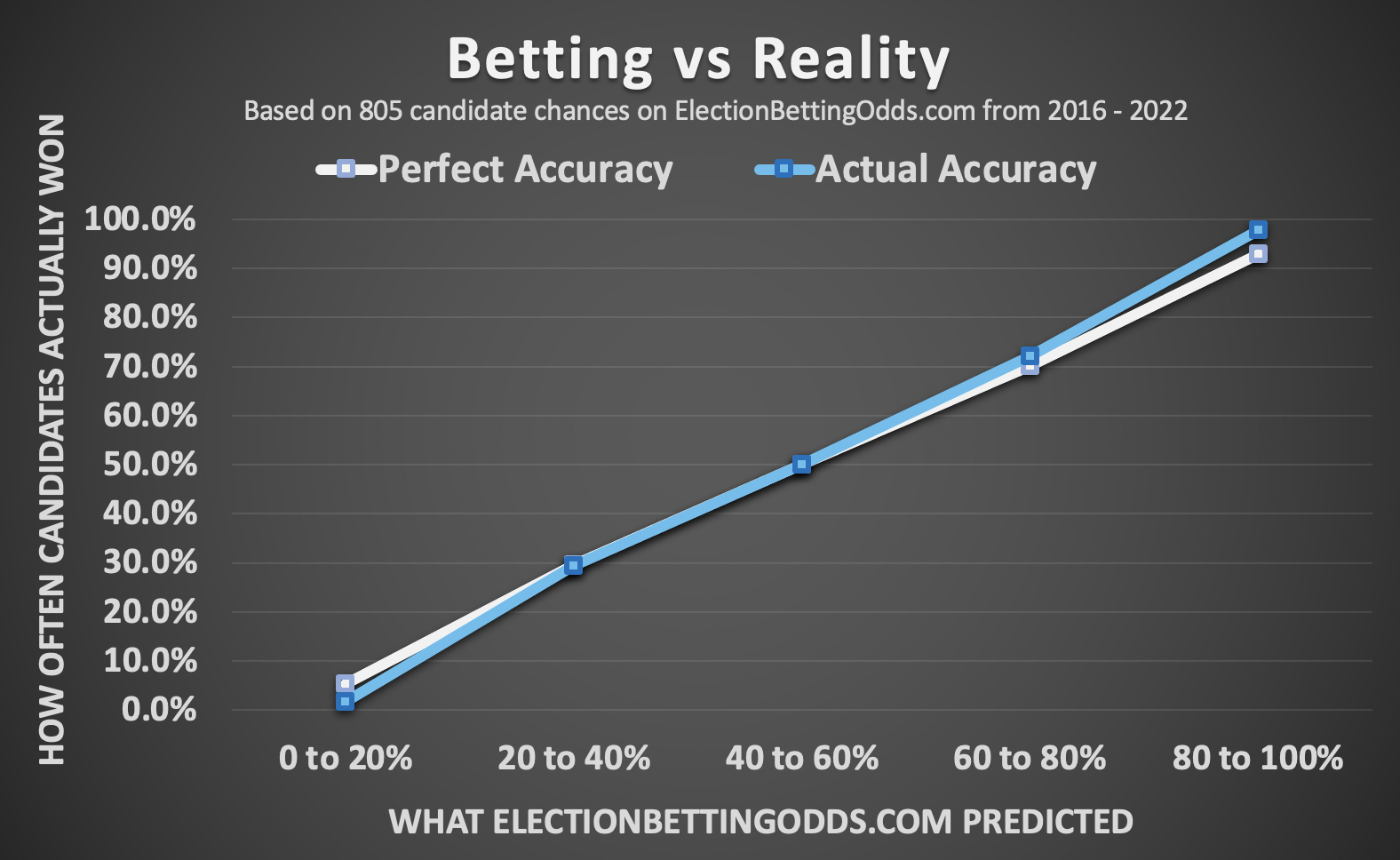
This is the calibration of the markets. If something that is predicted to happen 60% of the time actually happens that often, we say it’s well calibrated (and thus the name of this blog). We can also see the calibration for some other prediction sites here from calibration.city which has some excellent visualizations:
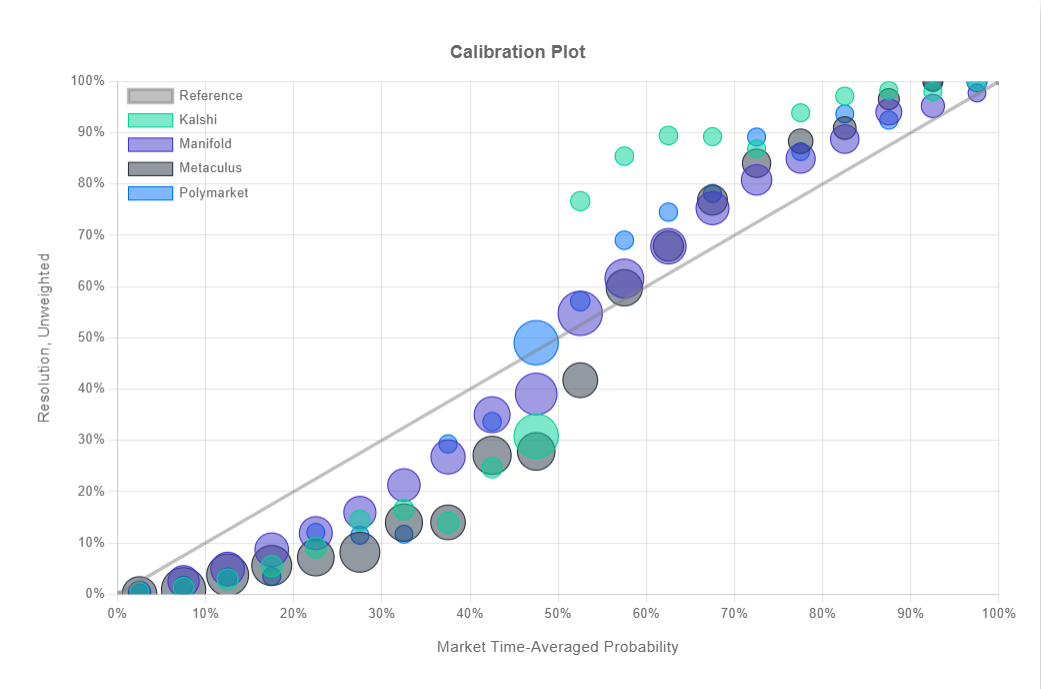
I suspect some of the systematic bias you see in the chart above and below the 50% mark is from the fact that many of these markets default to 50% and require betters to provide liquidity to move the market away from the start. To make an enticing market to bet in, the market makers have to incorrectly price a market so that bettors have an incentive to wager and earn their winnings, and we see this in the data as a the market makers systematically “betting” the wrong way to start the market. In fact, if you go to the calibration.city page and weight the y-axis for resolutions by market volume, this bias is reduced (since larger volume markets would have less weight on the initial price) although it does not disappear.
Alright, prediction markets are well-calibrated, but does that mean they are accurate? Are they actually predicting anything? Not necessarily!
Suppose we know that Republicans win the presidency about half the time and Democrats win the other half. We check the prediction markets and they always say democrats have a 50% chance to win. This is a well calibrated prediction, but it doesn’t actually tell us much information at any given point in time. We want to know about this particular upcoming election. What we can do then is use a Brier score to mathematically measure accuracy, and not just calibration. The Brier score is the means squared error for a set of predictions and their outcomes, and thus we can use it to measure the accuracy of probabilistic predictions. Here are the Brier scores from calibration.city:
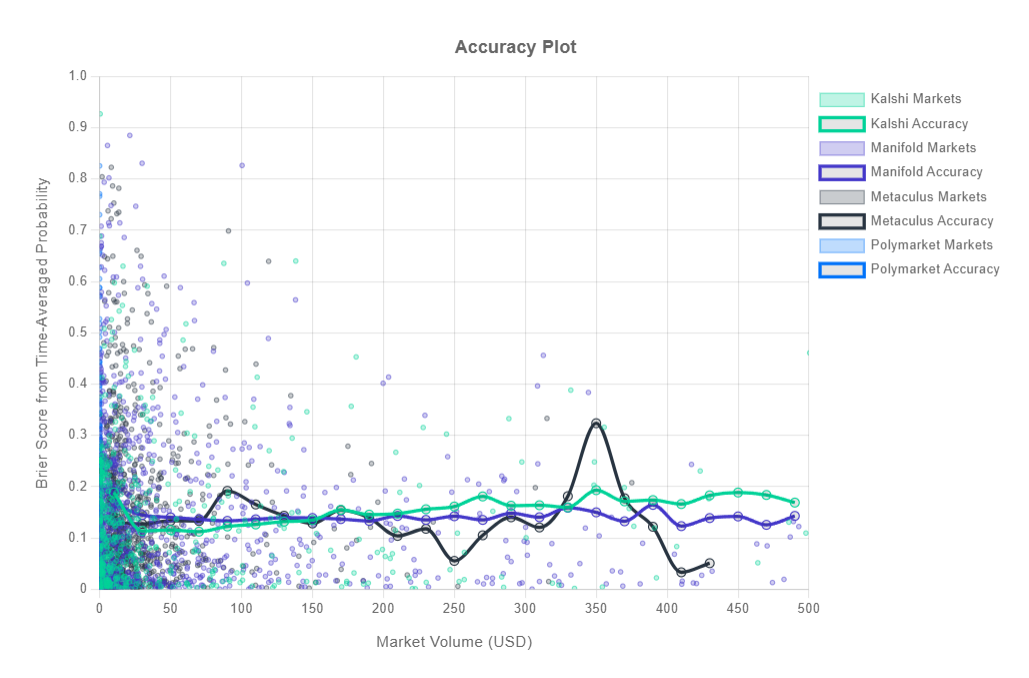
I arranged by market volume and did a time weighted average, but you can also try it yourself. Overall it seems market volume didn’t have much effect, perhaps because the existing Brier scores are already pretty low around 0.15, and also perhaps because higher volume markets could reflect exciting changes in the underlying event leading to both more uncertainty and more market trading.
We can actually decompose the Brier score into calibration, resolution, and uncertainty components, although exactly why this works is beyond my current statistical understanding. This stack exchange post was helpful, but unfortunately I don’t have the time to put together a full script to grab the data from Manifold and run the decomposition.
There’s also real limitations to comparing Brier scores. You’re really only supposed to compare them across the same events; if the underlying event is more uncertain, you would expect higher (worse) Brier scores. But Kalshi, Manifold, and Polymarket are all predicting slightly different things. The legal difficulties prediction market platforms face exacerbates the accuracy measurement problem; PredictIt has to limit the number and size of bets, Polymarket and Betfair are banned in the United States, and Manifold only uses play money. Still, you’d expect much of this to contribute to worse Brier scores. The fact that these are pretty solid is encouraging. If anyone wants to run an actual Murphy decomposition on prediction market data on a narrow topic, I would be interested to see the results.
I think we can still draw some conclusions though:
- Prediction markets are well calibrated: if they say something will happen with a given percentage chance, that’s actually a good estimate of how likely it will happen.
- Prediction markets have pretty good (low) Brier scores, and that puts an lower limit on how practically bad their resolution decomposition component could be even if they were perfectly calibrated.
- Prediction markets do all this despite major regulatory barriers.
The Bigger Picture
Taking a step back though, I think Matthew Green’s critique gets to something deeper: sure prediction markets are well calibrated in the face of uncertainty, but they don’t have any magical insight besides pushing the best guesses to the top. In other words, they’re not actually reducing the fundamental uncertainty in the world. Why is everyone so excited about this?
I think the answer is price discovery.
First let’s take the demand side. Perhaps you’ve looked up a prediction market price for an event and found the price to be…about what you expected.
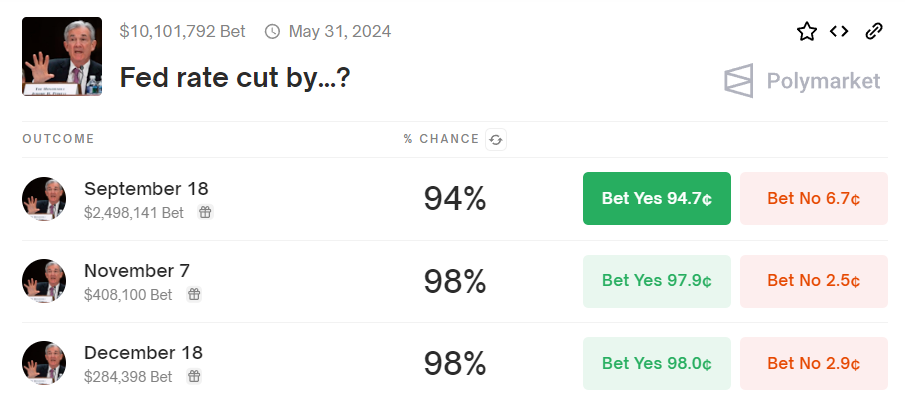
The Fed has been talking about rate cuts this year, they indicated in their last meeting that it’s likely coming and the market took a sharp tumble last week before recovering. It seems pretty obvious to anyone paying attention that the likelihood of a Fed rate cut by the end of the year is high. But not everyone was paying attention. A prediction market’s existence creates a publicly known “price” of the best estimate of whether an event will occur according to the market participants. Being able to know a well calibrated estimate of an uncertain event is a huge positive externality that prediction markets provide the whole world.
This is a big deal! If you don’t have a price to check, you’re left doing all the research yourself and you only have so much time. Worse, you might have to rely on very non-quantified pundit opinions with no track record. A price cuts through everything to give you a single best guess.
Next let’s take the supply side. Think about the amount of time, effort, resources, money, labor, algorithm design, etcetera that trading firms undertake to get an edge in financial trading. There are potentially billions of dollars on the line if you can correctly predict whether an equity or future will rise or fall in price. Prediction markets can harness these incentives to uncover truth not just about company financial data, but about anything we are curious about. They tie reality and truth about the world to financial incentives. They push us to discover information about what is happening and what will happen.
Unfortunately, they are also legally limited. Event based betting is for all practical purposes banned in the United States even though political decision making is very high stakes. Our lives are worse because of this! We should want our political decision-making processes scrutinized and better understood; prediction markets provide financial incentives to achieve those ends. Prediction markets could be providing us with real time information on whether Congress will pass legislation or how an administration will respond to crises.
Of course, the actual application of prediction markets could be much broader than politics. Nominal GDP futures markets could do a better job informing the Fed of forward looking expectations than stock markets or lagging economic data. Or imagine if we had an ongoing prediction market about possible pandemics on the horizon. That would have been very handy to refer to in January or February 2020 and may have alerted us sooner than simply relying on broad media reporting, which didn’t pick up the potential danger of the pandemic until early March.
Perhaps today prediction markets don’t tell us much besides aggregating some polling data, but if we legalized them, maybe they could tell us a lot more!
Uncharted Territory
The finance industry may be driven purely by profit, but the development of new financial instruments has actually brought all sorts of benefits, some of them very widely distributed. Index funds and ETFs allow regular people with savings access to market returns without needing to expose themselves to specific stock risk and at a fraction of the cost of mutual funds. Foreign exchange and commodity derivatives can help companies reduce their risk by locking in prices now; airlines are trying to run an airline business, not predict oil prices in six months.
Prediction markets could do even more if we let them.
A conditional prediction market is a single trading market with two events allowing investors to trade on the relationship between the two outcomes. For example, you could make a prediction market for a political parties’ election prospects conditional on whether they replace their candidate or not. Democrats took months to come around to the idea that their current presidential candidate might do poorly. If they had been able to compare conditional bets on who would win, they might have been able to select a different candidate much earlier!
Conditional markets could have all sorts of interesting applications. We could answer questions like “what will different policies’ impact be on unemployment next year?” or “which scientific research approach is most likely to improve 5 year survival rates of a major cancer?”. But I think the most important point to underline is that we don’t know because the markets aren’t allowed. It took a while to develop ETFs that regular investors could use for their retirement accounts. If we allowed people to experiment and try things, we could probably create some pretty cool things.
Even today, with all the legal challenges prediction markets face, they offer great value! People on Twitter will continue to claim that prediction markets are systemically biased or simply reflecting quirky beliefs of people overrepresented in the betting pool. I think this is too quick of a dismissal, but to some extent, they’re right! And I think it’s because you have to jump through a bunch of hoops to correct the markets and collect your winnings; as long as the CFTC wages a crusade against PMs, it will be challenging to make much money on them and thus they may often have incorrect prices. But we don’t have to live this way! We could look into the future if we allowed ourselves to.


{kind=link}